AI in locale
Lo stack Ollama + OpenWebUI accelerato in Vulkan sulla GPU della BC-250.
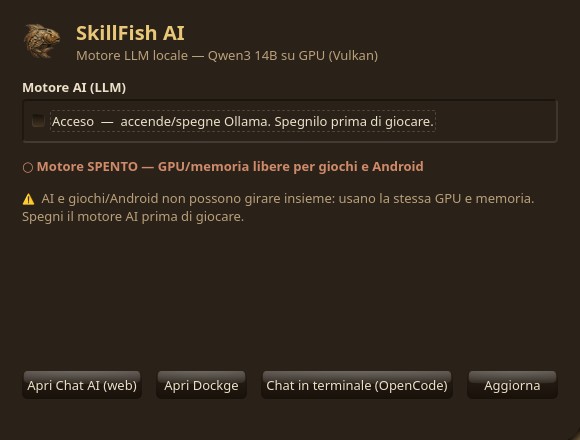
SkillFishOS include uno stack di intelligenza artificiale locale: modelli di chat e coding che girano interamente sulla GPU della BC-250, senza cloud e senza inviare dati all’esterno. Si accende e spegne con un clic, così da liberare GPU e RAM quando vuoi giocare.
Perché Vulkan e non ROCm
Lo stack AMD “ufficiale” per il calcolo è ROCm, ma non supporta la gfx1013 della BC-250. SkillFishOS usa quindi il backend Vulkan di Ollama, con i driver Mesa: funziona bene sulla GPU integrata sfruttando la memoria condivisa (e il GTT esteso, vedi GPU).
I componenti
| Componente | Ruolo |
|---|---|
| Ollama (backend Vulkan) | esegue i modelli LLM sulla GPU |
| OpenWebUI | interfaccia web di chat (con ricerca web) |
| Dockge | gestione degli stack Docker via web |
Lo stack gira in container Docker con un’immagine custom (Ollama + driver Vulkan di Mesa). È configurato per non avviarsi da solo (restart: "no"), così non sottrae la GPU ai giochi: lo attivi quando serve.
Il modello consigliato
Il modello pratico di riferimento è qwen3:14b: gira al 100% su GPU (~10.7 GB) con cache KV in f16.
⚠️ Su questo hardware (driver RADV) la quantizzazione
q4_0della cache KV corrompe l’output: va usata la cache f16.
Accensione/spegnimento
Un pannello AI dedicato (app nativa, vedi App native) accende e spegne l’intero stack con un clic. Tieni presente che:
- AI e giochi/Android non vanno usati insieme: condividono la stessa GPU e la stessa memoria;
- a stack spento, la GPU e la RAM tornano completamente disponibili per il gaming.
Fonti
- Ollama · OpenWebUI · Dockge
- Mesa / RADV (driver Vulkan)
- ROCm — hardware supportato (la
gfx1013non è in elenco)